昨天使用 Ohara 的 Web UI 建立了 Node 和 Workspace,所以已經把環境準備好了。 今天就可以操作關於 Pipeline 的功能,把資料從來源端流到目的端,做到資料 Producer 和 Consumer 的效果,中間使用 Topic 來存放資料。因此我們要使用 Pipeline 的功能之前需要在 cluster 的 workspace 先建立 Topic,如下圖: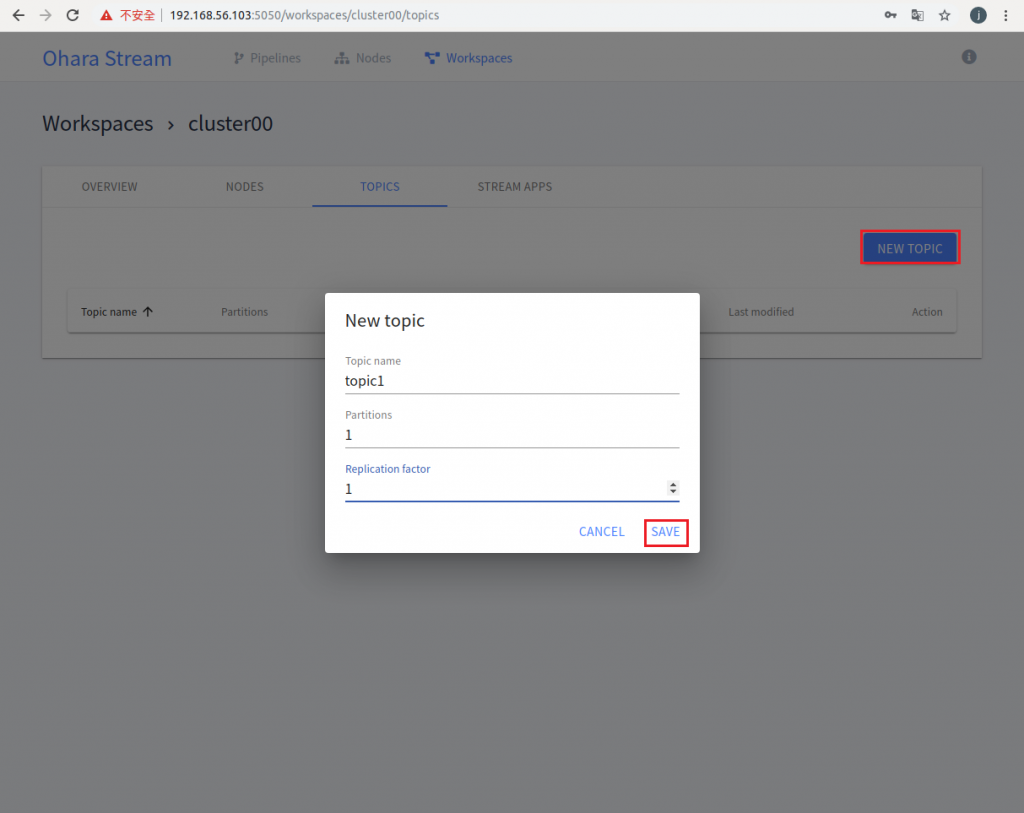
進入 cluster00 的 Workspace 之後點選 TOPICS 連結 -> NEW TOPIC -> 輸入 topic name、 partition 數量和 Replication factor 數量,因為目前只使用一台 node 所以這二個參數都輸入 1 -> 按下 SAVE 就可以執行建立 Topic 的動作。
Topic 建立完成之後,就可以建立 Pipeline 資料流。如下圖: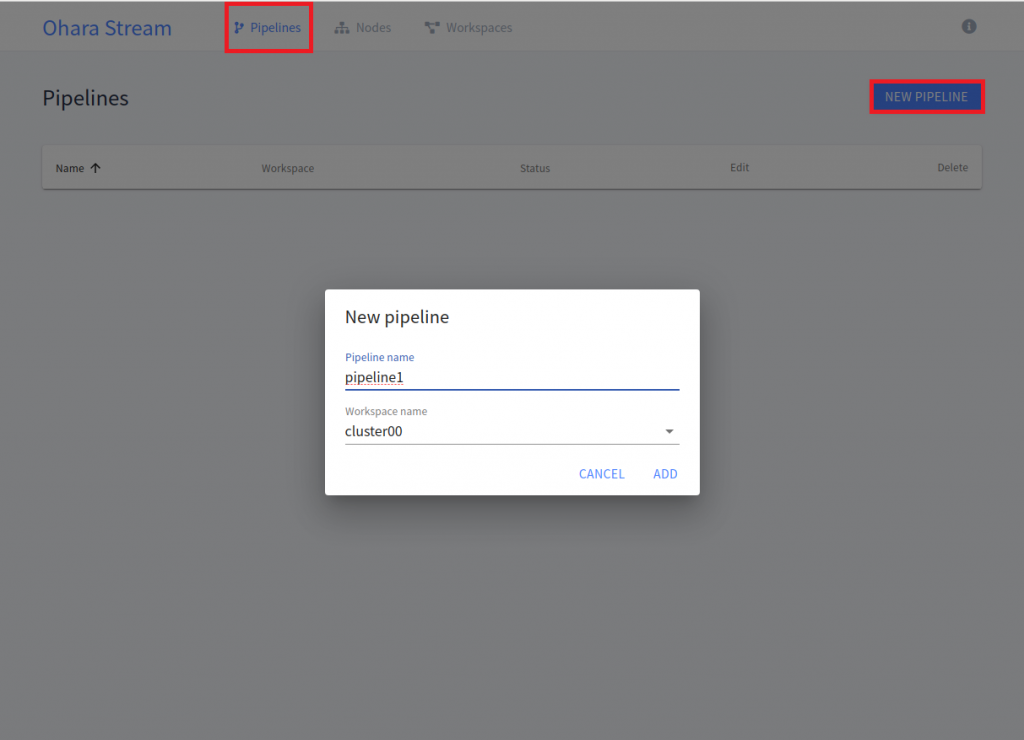
點選畫面上方的 "Pipeline" -> 然後按 "NEW PIPELINE " 按鈕 -> 輸入 Pipeline 名稱和選擇要使用哪個 workspace -> 按 "Add" 按鈕,這樣就可以建立一個 Pipeline,畫面如下: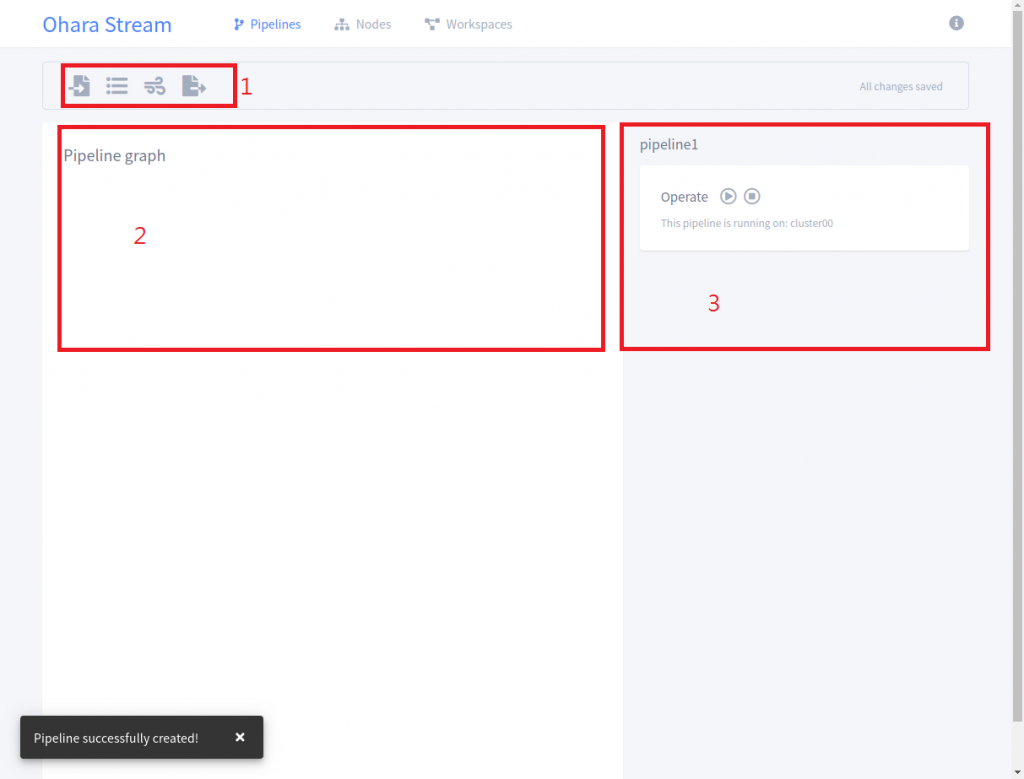
以下說明上圖 3 個區域所代表的功能:
第1個部份: 選擇我們要使用哪一種的 connector 類型、Topic 名稱以及 StreamApp 的類型
第2個部份: 顯示 Pipeline Grap 的畫面,讓我們可以看到資料流的 Overview,從來源端到目的端,經過了哪些的點
第3個部份: 主要用來設定來源端或是目的端的連線資訊,例如使用 JDBC Source Connector 我們就會設定 Database 連線的 JDBC URL、帳號和密碼。另外 Operate 是用來啟動執行 Connector或是暫停 Connector 的 Pipeline 執行
以下的 Demo 使用 PerfSource connector 來自動隨機產生資料, 資料會流到 Topic 裡,最後資料會流到 HDFS 裡。以下是簡單的 Demo 畫面:
1.選擇 Add a Source Connector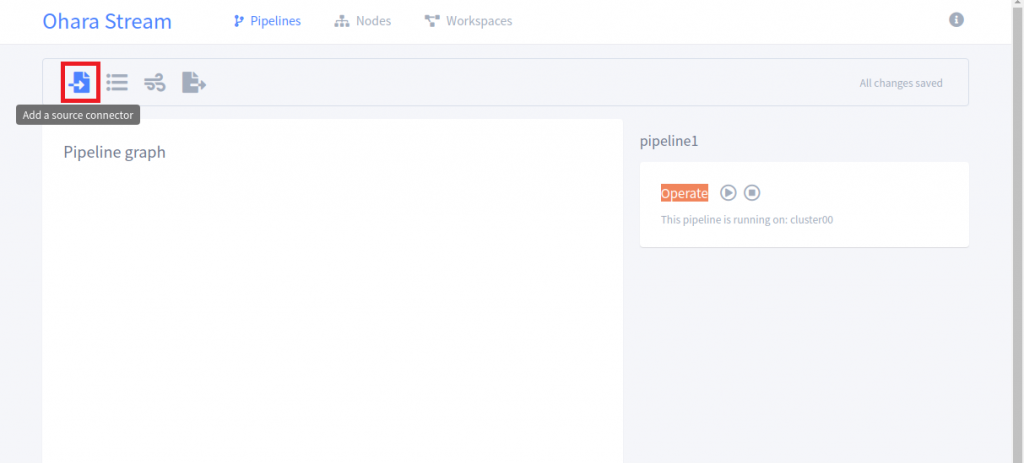
2.選擇 com.island.ohara.connector.perf.PerfSource 然後按下 Add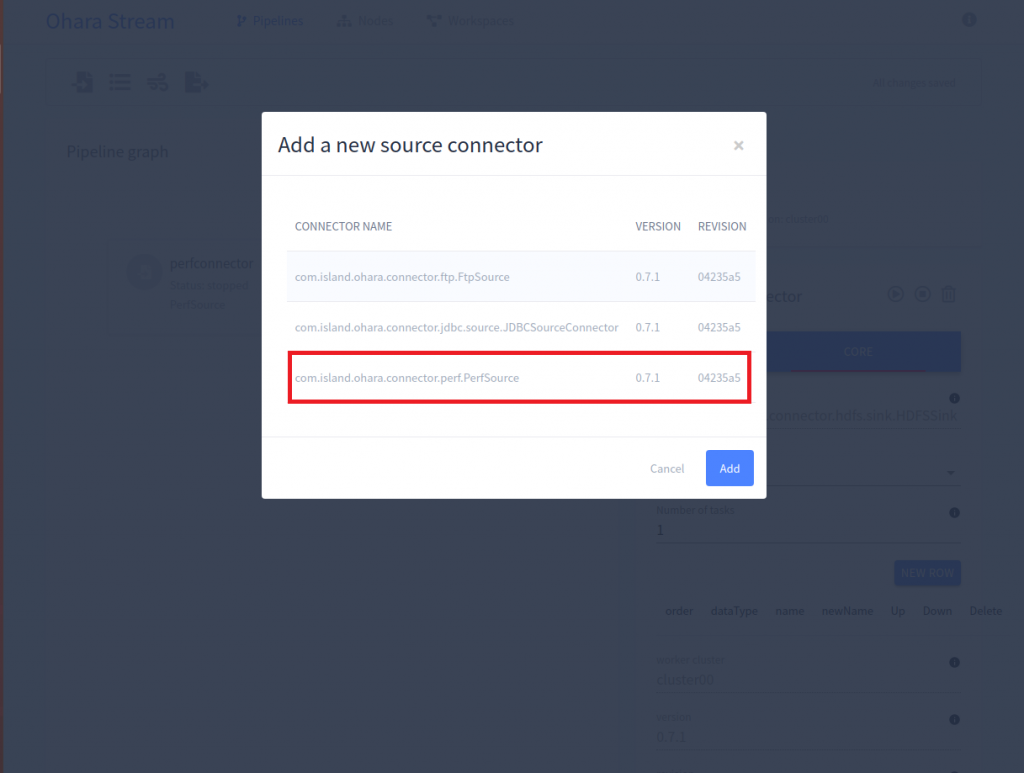
3.之後再來建立 Topic 和 HDFS Sink Connector
4.如果要讓 PerfSource Connector 的線連到 Topic,只要點選 perfconnector 的圖示按下右邊的 Core 的頁籤,然後選 topic1 就可以將 PerfSource Connector 連到 topic1,HDFS Sink Connector 也是相同的做法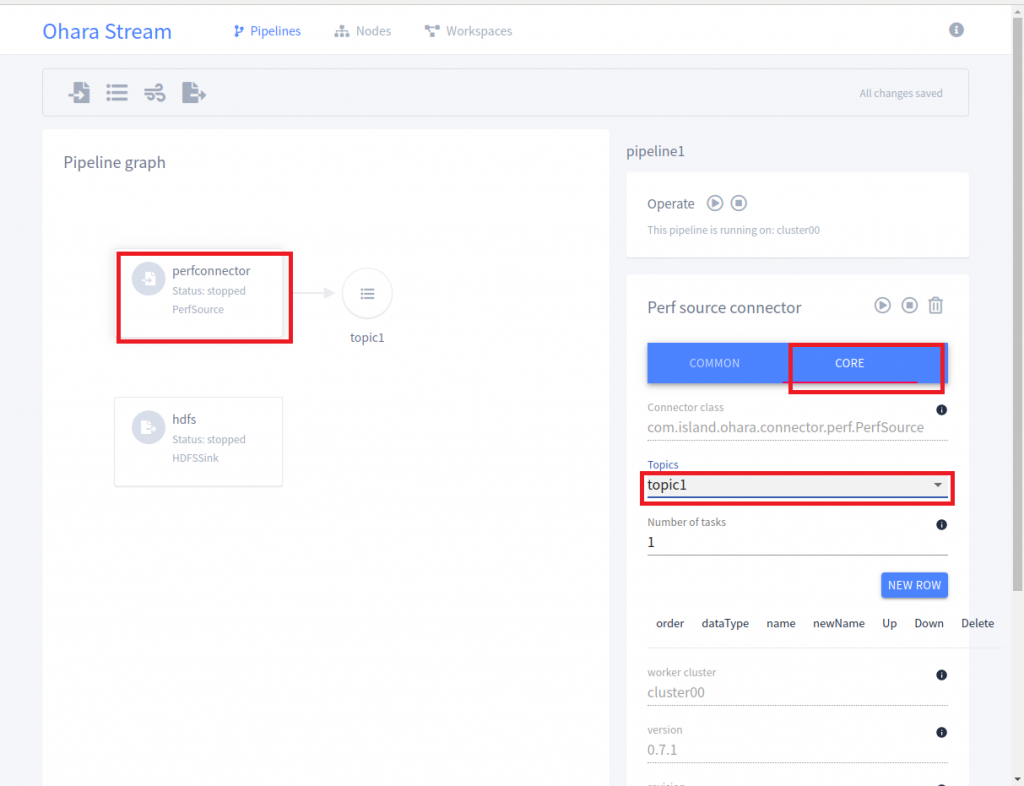
5.建立完 Pipeline 之後的畫面如下,只要點選右邊畫面的 Operator 的三角型按鈕就可以開始執行 Perf Source Connector 和 HDFS Sink Connector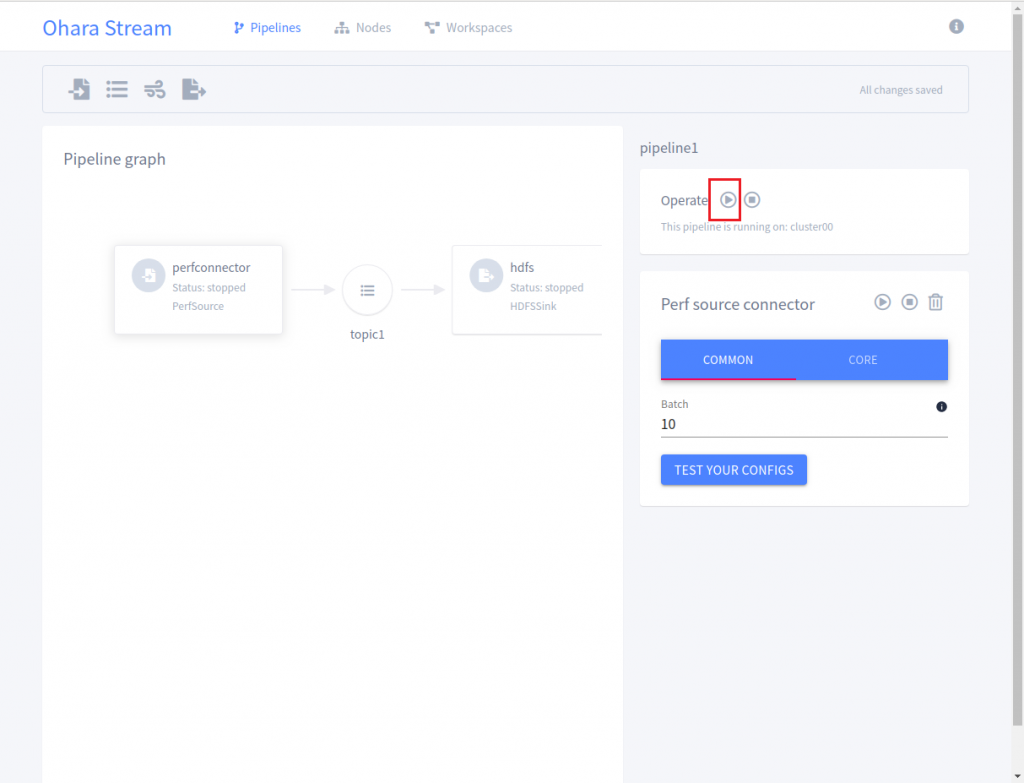
6.開始執行的畫面如下: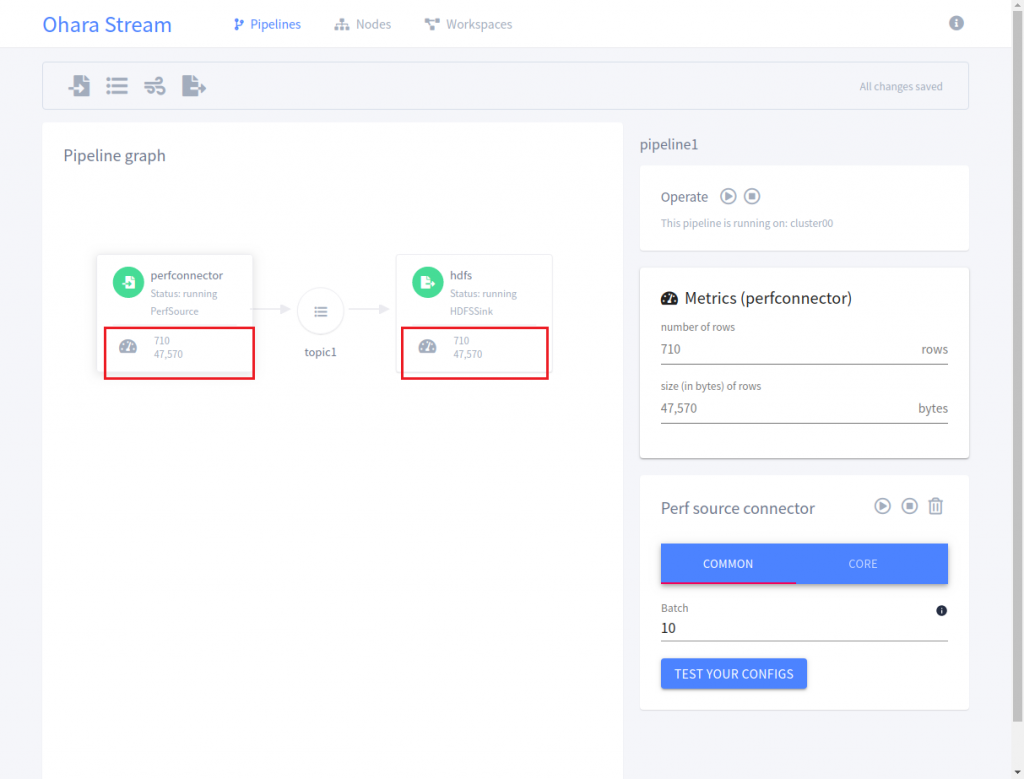
當 Perf Source Connector 和 HDFS Sink Connector 開始執行時,我們可以從 UI 上看到目前有多少的資料量被產生以及被寫入到 HDFS 裡了,可以幫助使用者簡單的監控目前的資料流狀態,以下是寫入到 HDFS 裡的資料內容:
1569131298210,1569131298210,1569131298210
1569131298210,1569131298210,1569131298210
1569131298210,1569131298210,1569131298210
1569131299211,1569131299211,1569131299211
1569131299211,1569131299211,1569131299211
1569131299211,1569131299211,1569131299211
1569131299211,1569131299211,1569131299211
1569131299211,1569131299211,1569131299211
1569131299211,1569131299211,1569131299211
1569131299211,1569131299211,1569131299211
1569131299211,1569131299211,1569131299211
1569131299211,1569131299211,1569131299211
1569131299211,1569131299211,1569131299211
1569131300212,1569131300212,1569131300212
這是隨機產生的資料主要是拿來測試使用,除了使用 PrefSource Connector,也可以使用 JDBC 或是 FTP Source Connector 來當原始資料。
今天已經 Demo 要如何使用 Ohara manager 的 WebUI,來建立 Connector 的資料流,之後還會再介紹有關於 StreamApp 的部份,做資料的過濾或轉換。


 iThome鐵人賽
iThome鐵人賽